Build Your Next
Large Model
Easily train and deploy your AI models, and gain scalable, optimized access to your organization's AI compute. Anywhere.
Book a demo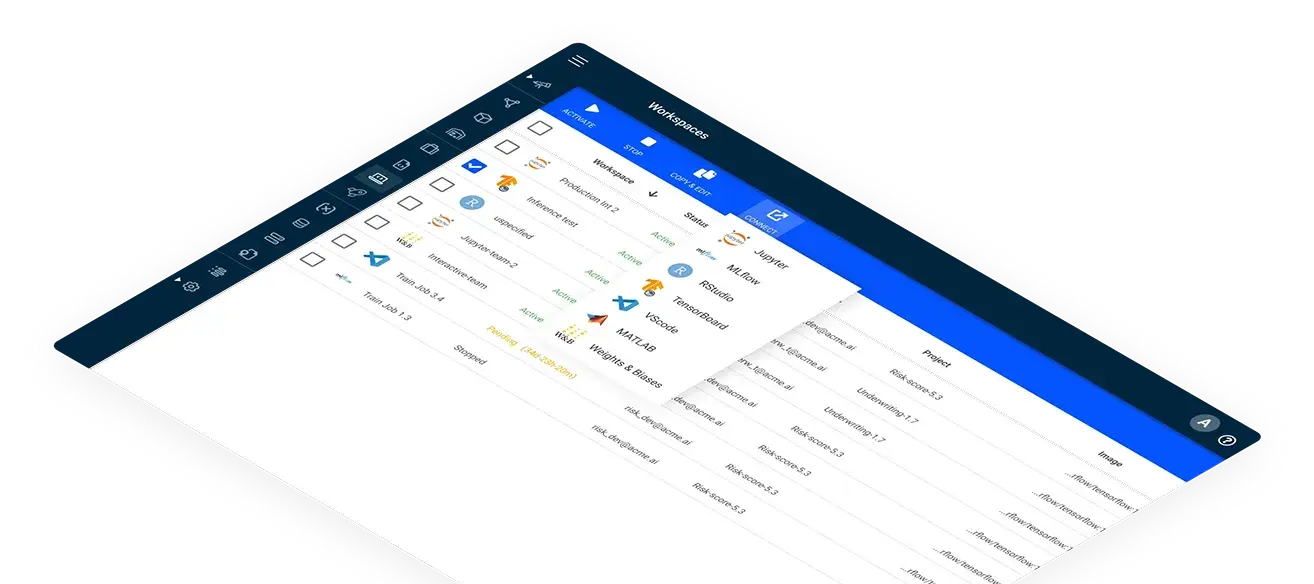

Bridging the gap between ML teams and AI infrastructure
Releasing large models is complex and requires powerful GPU resources.
Run:ai abstracts infrastructure complexities and simplifies access to AI compute with a unified platform to train and deploy models across clouds and on premises.

Accelerate AI development and time-to-market
Iterate fast by provisioning preconfigured workspaces in a click through graphical user interface and scale up your ML workloads with a single command line.
Get to production quicker with automatic model deployment on natively-integrated inference servers like NVIDIA Triton.

Multiply the Return on your AI Investment
Boost the utilization of your GPU infrastructure with GPU fractioning, GPU oversubscription, consolidation and bin-packing scheduling.
Increase GPU availability with GPU pooling, dynamic resource sharing and job scheduling.

Take your AI Clusters to the major league
Avoid resource contention with dynamic, hierarchical quotas, automatic GPU provisioning, and fair-share scheduling.
Control and monitor infrastructure across clouds and on premises, and protect your organization’s assets with features like policy enforcements, access control, IAM, and more.